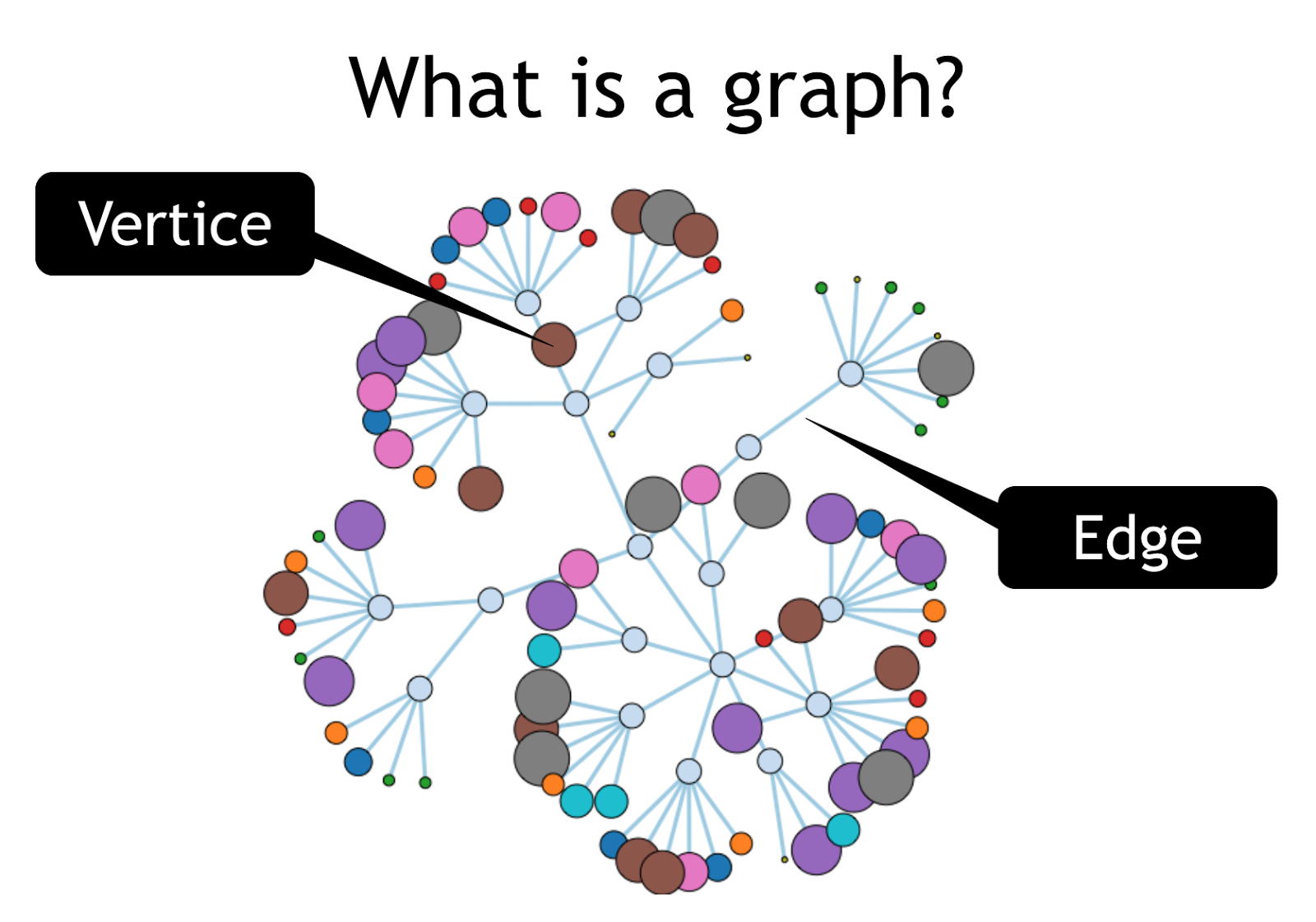
What is GraphGrid's Neo4j AWS Cloud?
GraphGrid's Neo4j AWS Cloud stage offers you a simple approach to run Neo4j Enterprise on Amazon Web Services. We have joined Neo4j + AWS to give expansive figuring limit that works all the more rapidly and flawlessly by uniquely uniting the local diagram database Neo4j with Wide Area Network (WAN) organizations crosswise over 12 land AWS Regions around the globe.
Amazon Web Services is situated in 12 locales: US East (Northern Virginia), lion's share of AWS servers are based here, US West (northern California), US West (Oregon), Brazil (São Paulo), Europe (Ireland and Germany), Southeast Asia (Singapore), East Asia (Tokyo and Beijing), Asia Pacific (Seoul) and Australia (Sydney). Also, every district has different "Accessibility Zones" which are really particular server farms offered by AWS administrations.
For an ideal worldwide affair, we have utilized Geo load-adjusting strategies with AWS Elastic Load Balancers since it will naturally convey approaching application movement crosswise over various Amazon EC2 occurrences in the cloud. This progression of our affirmed Neo4j expert's ensures that the solicitations are served from the best AWS areas to accomplish low dormancy levels and in addition consistently furnishing adaptation to internal failure with the exact measure of burden adjusting ability to bolster the programmed failover situations.
Why we have incorporated with AWS
Some key advantages of incorporating with AWS to begin:
Security:
AWS has built world-class base both physically and over the web to stay versatile in the disappointment mode, common catastrophes or even framework disappointments. Additionally, they are using a conclusion to-end approach which guarantees your information is totally secured.
Adaptable:
Influence the force of the AWS worldwide framework and disregard the mystery in distinguishing your foundation needs. The AWS cloud limit is accessible with granular adaptability to exploit on interest, spot and saved occurrences for consistent state and burst situations.
Worldwide Leader:
Amazon holds an incredible vicinity over the globe with 12 districts, 37 accessibility zones and more than 50 edge areas. Additionally, AWS has executed the most recent advancements by which you can without much of a stretch access to process and capacity assets according to your prerequisite.
Utilizing Advanced AWS Cloud Capabilities for GraphGrid Data Platform (GGDP)
Our GraphGrid Data Platform (GGDP) influences best practices of Amazon Web Services (AWS) for security, information administration, information access and information coordination. Our GGDP is architected for the endeavor in this manner, it offers organizations over every one of the Regions and Availability Zones of AWS.
Be that as it may, all occurrences are conveyed in a Virtual Private Cloud (VPC), each being ordered in a Neo4j Cluster which is dispatched with a Security Group permitting access inside of Cluster possessed Subnets. Furthermore, on the off chance that you need to extend your present security answers for a higher evaluation, GraphGrid additionally gives security alternatives on your solicitation, for example, encryption and unscrambling to secure your information